How I Beat NVIDIA NCCL by 2.4x
![]()
TL;DR: I built a 2-GPU NVLink AllReduce library that outperforms NVIDIA NCCL by 1.2x-2.4x with 50x+ more stable tail latency. The key insight: apply principles from high-performance systems to GPU communication.
The Problem
NCCL is the de facto standard for GPU collective operations. It's battle-tested, supports any topology, any GPU count. But for the common case of 2 GPUs on NVLink, it leaves performance on the table.
Why? NCCL's ring algorithm uses NVLink unidirectionally - one direction at a time, sequentially. On a 2-GPU system, this wastes half your bandwidth.
The Solution
YALI (Yet Another Low-Latency Impl) exploits bidirectional NVLink simultaneously. Both GPUs read from each other at the same time:
NCCL Ring (Sequential) YALI (Simultaneous)
====================== ===================
Step 1: GPU0 → GPU1 BOTH AT ONCE:
Step 2: GPU1 → GPU0 GPU0 reads from GPU1
Step 3: GPU0 → GPU1 GPU1 reads from GPU0
Step 4: GPU1 → GPU0
4 sequential steps 1 parallel step
~78% SoL max ~87% SoL achieved
Results
Profiler-Verified Performance (nsys)
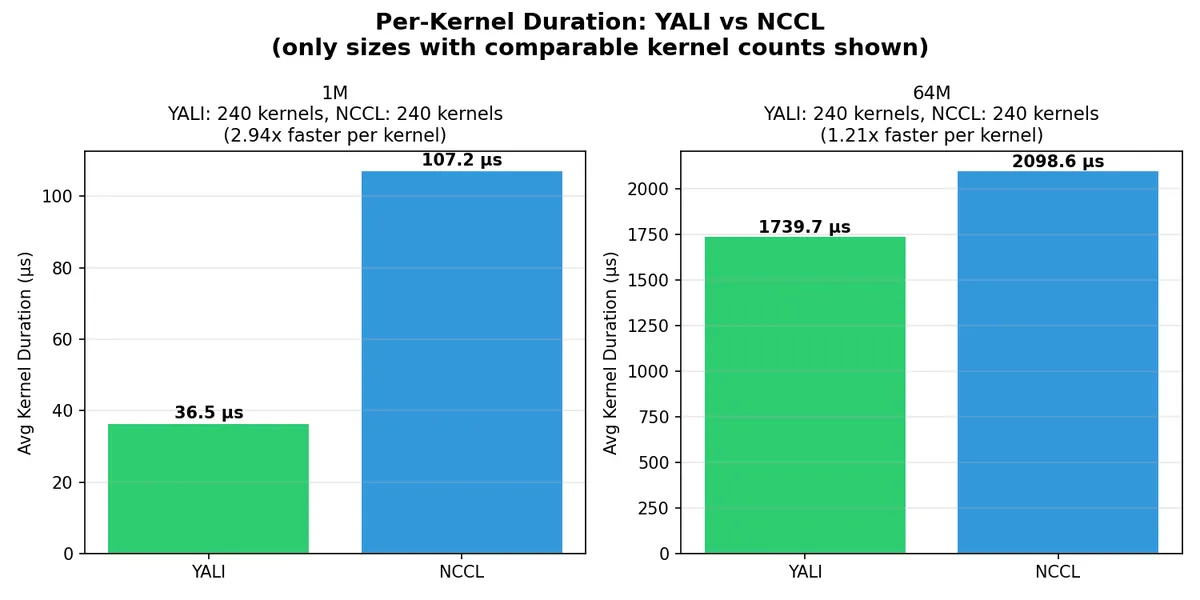
At 1MB: 2.94x faster per kernel (36.5µs vs 107.2µs) At 64MB: 1.21x faster per kernel (1739.7µs vs 2098.6µs)
Peak Bandwidth by Data Type
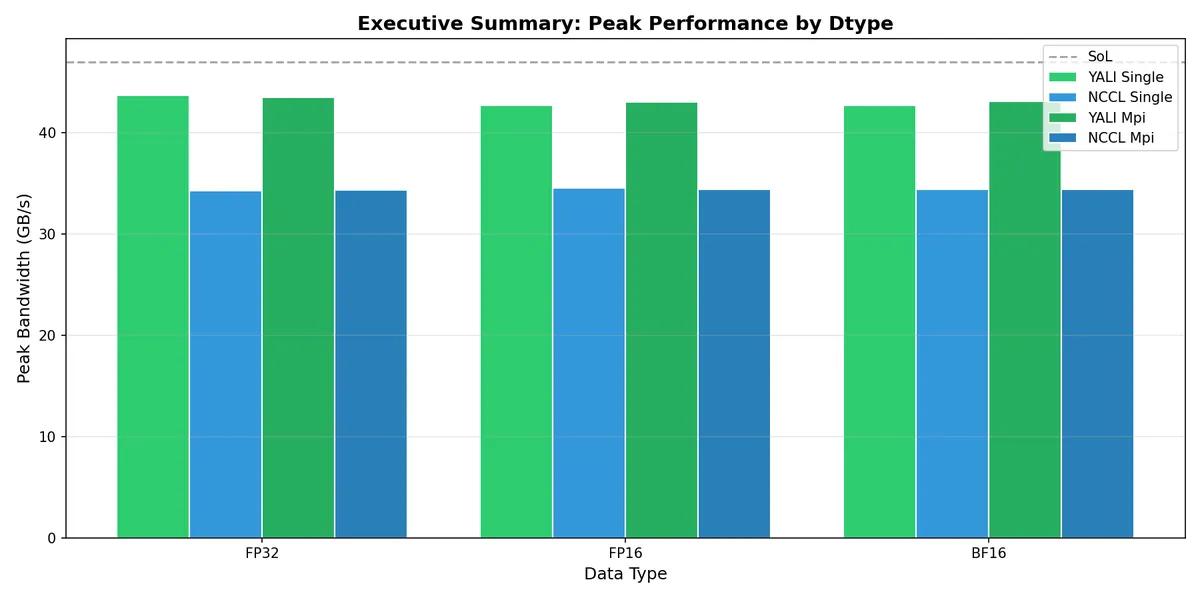
YALI achieves 44 GB/s peak vs NCCL's 34 GB/s - consistently across FP32, FP16, and BF16.
The Performance Principles
The magic isn't in clever algorithms - it's in applying high-performance computing principles proven in low-latency systems, distributed databases, and lock-free data structures:
1. Static Scheduling
Hardware likes predictability. No runtime negotiation, no dynamic decisions.
Lane/CTA Static Work Assignment - Each thread block knows its exact work slice at compile time:
const int blockId = blockIdx.x;
const int lane = blockId % laneCount;
const int laneCta = blockId / laneCount;
const size_t elemsPerCta = (totalElems + ctasPerLane - 1) / ctasPerLane;
const size_t startElem = min(laneCta * elemsPerCta, totalElems);
Static Tuning Heuristics - Lane counts determined by message size, not runtime probing:
inline int FlashLanePreset(size_t bytes, DType dtype) {
if (bytes <= (256ull << 10)) return 16; // <=256K
if (bytes <= (4ull << 20)) return 32; // 1M-4M
if (bytes <= (16ull << 20)) return 16; // 16M
return 32; // 64M
}
2. Pre-fetching
Hide memory latency by fetching the next chunk while processing the current one.
Staged Prefetch with cp.async - Non-blocking GPU memory copies:
auto prefetchStage = [&](int stageIdx, int bufIdx) {
// cp.async.cg.shared.global - async copy from peer GPU to shared mem
asm volatile("cp.async.cg.shared.global [%0], [%1], 16;\n" ...);
asm volatile("cp.async.commit_group;\n" ::);
};
3-Stage Double-Buffering - Pipeline hides all memory latency:
Time →
Stage 0 Stage 1 Stage 2 Stage 0
| | | |
v v v v
┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐
│FETCH │ │FETCH │ │FETCH │ │FETCH │
│chunk0│ │chunk1│ │chunk2│ │chunk3│
└──┬───┘ └──┬───┘ └──┬───┘ └──┬───┘
│ │ │ │
└────┐ └────┐ └────┐ │
v v v v
┌──────┐ ┌──────┐ ┌──────┐
│REDUCE│ │REDUCE│ │REDUCE│
│chunk0│ │chunk1│ │chunk2│
└──────┘ └──────┘ └──────┘
3. Pre-allocation
Amortize setup costs. Allocate once, reuse forever.
Pre-allocated Device Args - No per-call allocation:
// Allocated ONCE during Comm construction
args0_host.resize(kMaxLanes); // 128 lanes max
cudaMalloc(&args0_dev, kMaxLanes * sizeof(YaliLaunchArgs));
Source: allreduce.cuh#L109-L144
Ring Buffer Pre-sizing - Capacity calculated upfront:
size_t capacity = (lane_bytes + slot_bytes - 1) / slot_bytes;
cudaMalloc(&rings[lane].sequence, capacity * sizeof(uint64_t));
cudaMalloc(&rings[lane].data, capacity * slot_bytes);
Source: allreduce.cuh#L388-L458
4. Memory Ordering
GPU memory ordering is subtle. Get it wrong and you get silent corruption.
Acquire-Release Semantics - Cross-GPU visibility:
__device__ inline void store_release_u64(uint64_t* addr, uint64_t value) {
__threadfence_system(); // Flush writes before store
*reinterpret_cast<volatile uint64_t*>(addr) = value;
}
__device__ inline uint64_t load_acquire_u64(const uint64_t* addr) {
uint64_t value = *reinterpret_cast<const volatile uint64_t*>(addr);
__threadfence_system(); // Sync L2 after load
return value;
}
Summary: Hardware-Software Mapping
| Hardware Concept | Software Principle | Implementation |
|---|---|---|
| Static scheduling | Deterministic lane/CTA assignment | flash.cuh:49-64 |
| Static scheduling | Pre-computed sequence bases | allreduce.cuh:615-630 |
| Pre-fetching | cp.async staged prefetch | flash.cuh:97-132 |
| Pre-fetching | Double-buffering wait groups | flash.cuh:134-150 |
| Allocation | Pre-allocated device args | allreduce.cuh:109-144 |
| Allocation | Ring buffer pre-sizing | allreduce.cuh:388-458 |
| Memory ordering | Acquire-release semantics | ring.cuh:36-49 |
Try It Yourself
#include "src/ops/allreduce.cuh"
// Setup (once)
yali::Comm comm(0, 1); // GPU 0 and 1
// AllReduce: recv = send0 + send1
yali::allreduce(comm, send0, recv0, send1, recv1, count);
Full code: examples/simple.cu
git clone --recursive https://github.com/Venkat2811/yali
cd yali && make setup && make build-all
CUDA_VISIBLE_DEVICES=0,1 bazel-bin/benchmark_yali 16777216 20 cuda-events
The Name

Yali (யாழி / யாளி) is a composite creature from Tamil and South Indian temple architecture - part lion, part elephant, part serpent. Like the sphinx or griffin in other cultures, it represents a guardian figure.
Yet Another Low-Latency Impl - guarding your GPU efficiency.
Built in collaboration with Claude Code and Codex CLI
GitHub: https://github.com/Venkat2811/yali
Citation
If you use YALI in your research or project, please cite:
Venkat Raman. "YALI: Yet Another Low-Latency Implementation". GitHub (2026).
https://github.com/Venkat2811/yali
@misc{venkat2026yali,
title = {YALI: Yet Another Low-Latency Implementation},
author = {Venkat Raman},
year = {2026},
publisher = {GitHub},
url = {https://github.com/Venkat2811/yali}
}